

The How To Decode A Website exercise was a challenging one, involving many complex pieces of code and two new Python modules. When appropaching problems like this one, it helps to develop a plan for the program before executing it.
Our plan should be as follows:
requests library to load the HTML of the page into PythonWe will go through each of these steps in this detailed description.
First, take a look at the full program without any comments:
Let us break this down piece by piece and line by line.
Line 1:
import requestsFirst, install the requests library according to the official documentation and your operating system, then import the library into the program.
Next,
from bs4 import BeautifulSoupInstall BeautifulSoup according to the installation documentation. Importing the library is not like the usual way of import foo. Reading the import / useage documentation is the right approach.
Next:
base_url = 'http://www.nytimes.com'
r = requests.get(base_url)These lines make the request to the New York Times homepage. Making a request is simple, according to the documentation you supply a URL and make a GET request.
soup = BeautifulSoup(r.text)Reading further through the documentation, we discover that r, contains all the information from the request sent to the New York Times homepage. What we actually want is to look at the HTML of the page and analyze it, so we find that r.text returns all the HTML from the returned request.
After this, BeautifulSoup is the tool we use to recode the HTML. In the same documentation that describes how to import BeautifulSoup, it describes how to import the HTML to analyze it in Python using the line of code in line 6.
Next we need to figure out what exactly we need to look for in the HTML decoding of the New York Times webpage. I will explain how to do this in the Chrome browser - it works in other browsers but the instructions may be slightly different. Right-click on the page, and click “Inspect Element.” Like so:
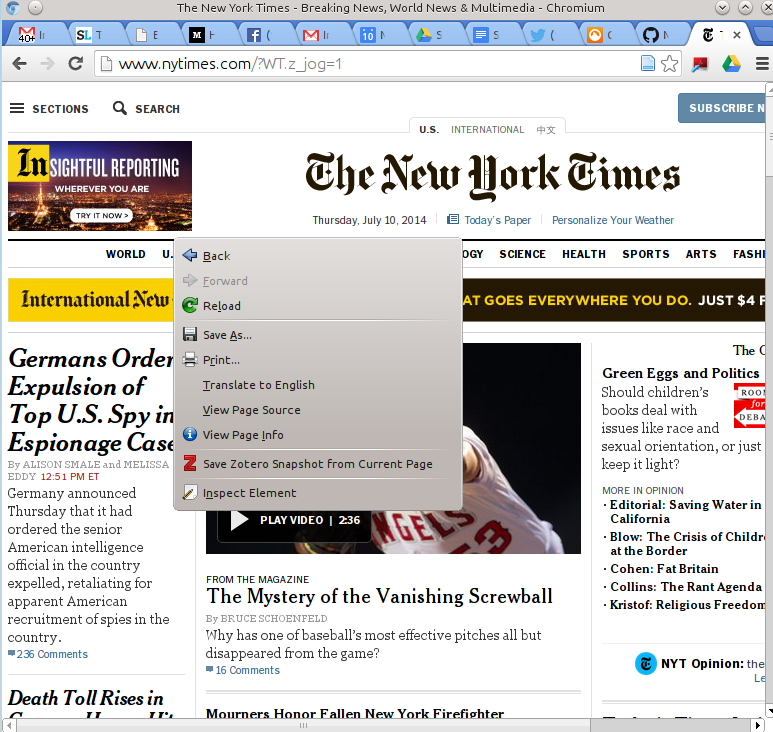
What pops up at the bottom of the page contains all the HTML that makes up the page. Let us now find the HTML that exactly describes the headlines of the main page. Pick a headline - let’s take “Germans Order Expulsion of Top U.S. Spy in Espionage Case”. Now click the magnifying glass at the bottom of the page:
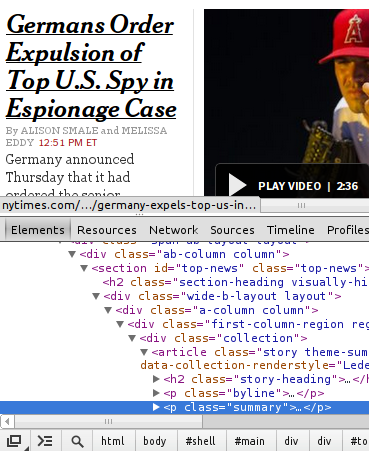
And move the mouse to click on the title we chose. You can see that at the bottom of the page in the HTML bar, we see the line
<h2 class="story-heading"> .. </h2>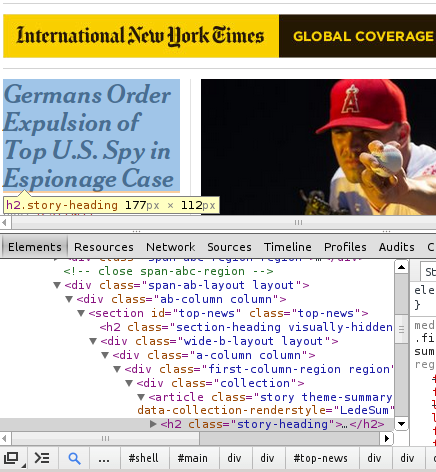
Our working assumptions for the moment is that all of the story titles are embedded inside some kind of HTML tag with a class called story-heading. Confirm with another title or two to make sure this assumption is correct, which it is.
Now that we know we are looking for all elements on the page with the class story-heading, so we need to find the documentation for how to do that, with special instructors for how to do this for a class. We end up with:
soup.find_all(class_="story-heading")This returns a list of all tags with story-heading as a class. What we need to do is loop through all of them with a for loop and see what format the output is in.
for story_heading in soup.find_all(class_="story-heading"):
print(story_heading) <h2 class="story-heading">...If you scroll through the list of outputs, they come in two varieties:
When we loop through the lines with story-heading, we need to take this difference into account using more BeautifulSoup magic:
for story_heading in soup.find_all(class_="story-heading"):
if story_heading.a:
print(story_heading.a)
else:
print(story_heading)To see this output:
<a href="http://www.nytimes.com/2014/07/11/...And then remove the text from the link and the title from the list of contents:
for story_heading in soup.find_all(class_="story-heading"):
if story_heading.a:
print(story_heading.a.text)
else:
print(story_heading.contents[0]) Germans Order Expulsion of Top U.S. Spy in Espionage Case
Death Toll Rises in Gaza, as Hamas Hits New Targets in Israel
...We are almost there! The only thing missing is the formatting - if you scroll through the list of outputs, the formatting of some titles farther down the list. There are an excess of spaces, so stripping the strings and replating all instances of new lines and tabs with regular spaces should do the trick. Take a look at the Python string methods documentation.
And this is how we get lines 8 through 12:
for story_heading in soup.find_all(class_="story-heading"):
if story_heading.a:
print(story_heading.a.text.replace("\n", " ").strip())
else:
print(story_heading.contents[0].strip())And we have our list of titles!
Germans Order Expulsion of Top U.S. Spy in Espionage Case
Death Toll Rises in Gaza, as Hamas Hits New Targets in Israel
...Take a look the full program with all it’s comments here:
Here are some user solutions!